Week 6
Computational
Text Analysis
Soci—316
Text As Data
March 3rd
Some Updates
Qualtrics Survey Assignment
Qualtrics Survey Assessment Deadline
Your Qualtrics survey assignments are now due by 8:00 PM on Friday, March 6th.
Some Updates
Qualtrics Survey Assignment
Some Updates
Annotated Bibliography
Annotated Bibliography Deadline
Your annotated bibliographies are now due by 8:00 PM on Sunday, March 15th.
Some Updates
Annotated Bibliography
A Reminder
Click to Expand Flyer

The Coming Weeks
Setting the Stage
A Mainstream Technique
Computational text analysis is in its heyday. The availability of unprecedented volumes of digitized content, the development of sophisticated methods for extracting meaning from such data, and the rapid upgrading of the relevant technical expertise among practitioners—all fueled by the cross-pollination of ideas between computer science, engineering, linguistics, and the social sciences, as well as between academia and industry—have brought this mode of empirical inquiry into the scholarly mainstream.
(Bonikowski and Nelson 2022:1470, EMPHASIS ADDED)
Stylized Example
Topic Models
Stylized Example
Word Embeddings
Target Concept
MIGRATION
Click a concept ...
0.00
COSINE SIMILARITY IN HYPERSPACE
Stylized Examples
Leveraging Large-Language Models
PROMPT TO LARGE LANGUAGE MODEL
"Review these snippets and tell me the most likely discursive category they belong to (IMMIGRATION, ECONOMY, or CLIMATE CHANGE) based on the semantic patterns you detect."
PREDICTED DISCURSIVE CATEGORY
TOPIC
PROBABILITY OR CONFIDENCE
0%
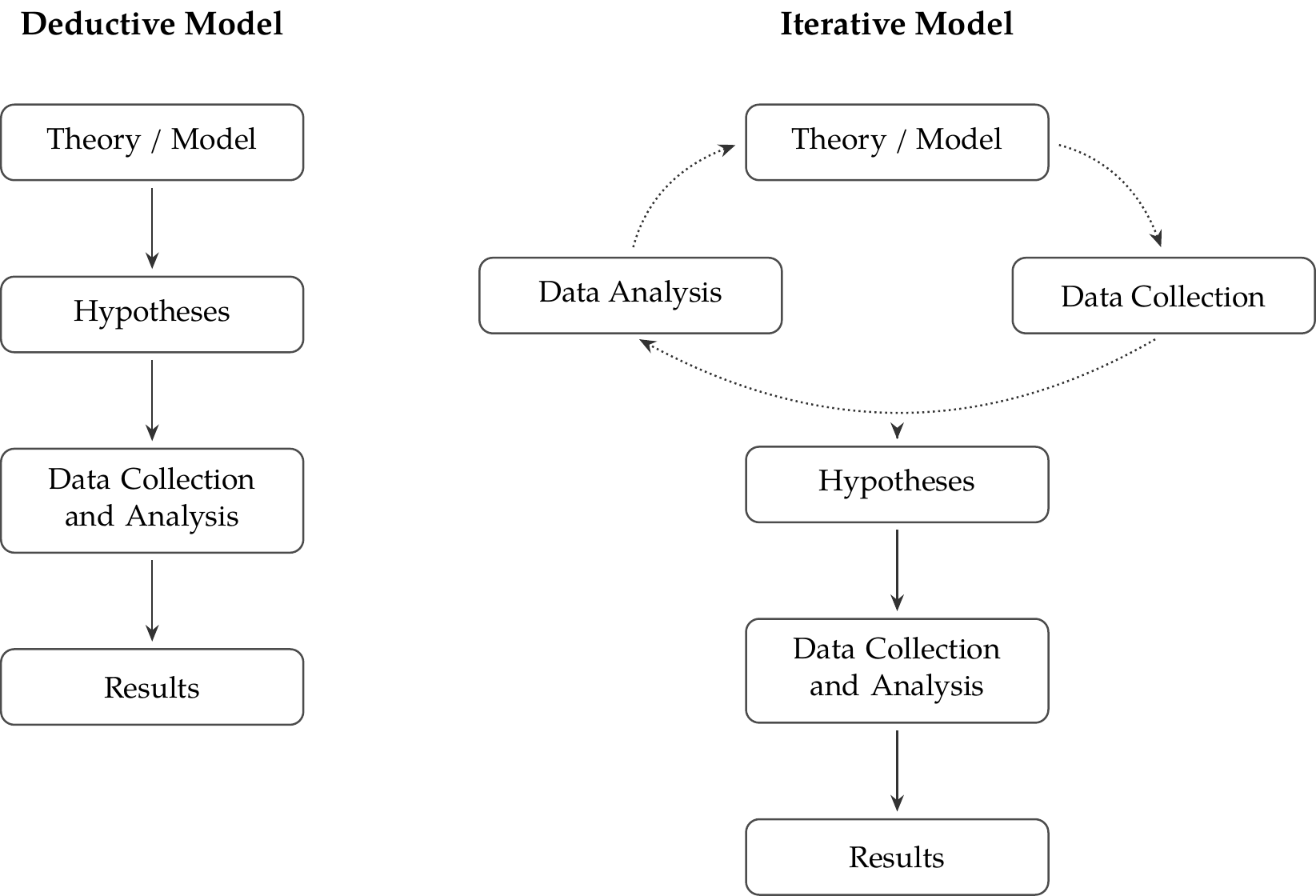
Deduction, Induction, and the Analysis of Textual Data
Towards an Iterative Model
[R]esearchers often discover new directions, questions, and measures within their quantitative data … If the standard deductive procedure is followed too closely and data is only collected at the very last minute, researchers might miss the opportunity to refine their concepts, develop new theories, and assess new hypotheses. A great deal of learning happens while analyzing the data. Even when a research project starts with a clear question of interest, it frequently ends with a substantially different focus.
(Grimmer, Roberts, and Stewart 2022:14, EMPHASIS ADDED)
Towards an Iterative Model
Regardless of how the research was actually conducted, standard practice of writing articles begins by stating the theory, its observable implications, and the measurement strategy; then the dataset is introduced. This poses a problem for inference if a researcher—even unintentionally—presents a theory as if it is being applied to a fresh dataset when in fact the same data is being used both to develop and to test the theory of interest … Acknowledging that we regularly engage in induction to refine the methods of discovery and then rigorously test these discoveries would greatly improve how we conduct social science.
(Grimmer et al. 2022:14, EMPHASIS ADDED)
Towards an Iterative Model
Click to Expand Diagram
Adaptation of Figure 2.1 in Grimmer, Roberts, and Stewart (2022)
Towards an Iterative Model
[T]hinking iteratively is the best approach for analyzing text as data … As in the standard model, we begin with an interesting question, insight, or specific dataset. But rather than suppose that our theories are completely developed before looking at data, we emphasize that iteratively examining data and refining theories help us to clarify our theoretical insights. After this inductive process, the researcher must then obtain new data on which to test the refined theories.
(Grimmer et al. 2022:15, EMPHASIS ADDED)
Towards an Iterative Model
The need for a more inductive model of social science research is not new; nor is it specific to text. However, because of the high informational content and richness of text data, an inductive approach can be helpful at the early stages of a research project—when scholars are formulating their intuitions—as well as at the later stages of the research process … [T]ext as data can contribute to inference at three stages of the research process: discovery, measurement, and inference.
(Grimmer et al. 2022:15, EMPHASIS ADDED)
Group Exercise
Discovery, Measurement, Inference
Grimmer et al. (2022:15–17) argue that treating text as data can facilitate discovery, measurement, and inference throughout the research process.
In groups of 2-3, complete the following tasks:
Review and discuss what Grimmer et al. (2022) mean by discovery, measurement, and inference.
Describe how you could use textual data to discover, measure, or draw inferences related to your topic of interest.
Six Principles of Text Analysis
Key Principles
Adaptation of Table 2.1 in Grimmer et al. (2022)
| 1 | Social science theories and substantive knowledge are essential for research design. |
| 2 | Text analysis does not replace humans—it augments them. |
| 3 | Building, refining, and testing social science theories requires iteration and cumulation. |
| 4 | Text analysis methods distill generalizations from language. |
| 5 | The best method depends on the task. |
| 6 | Validations are essential and depend on the theory and the task. |
Key Principles
(1) Theory Is Essential
Indeed, the onslaught of massive collections of texts and new statistical models makes theoretical reasoning more, not less, important. Rather, these massive datasets help researchers to think more precisely about their theoretical relationships because the increase in data often allows them to test hypotheses that previously they would have had too little data to test … Quite contrary to proclamations that theory will end and humans will be obsolete, many … (text-based) models … are useful only with deep and close interpretation from analysts.
(Grimmer et al. 2022:24, EMPHASIS ADDED)
Key Principles
(2) Text Analysis Augments Human Capacity
Text data is already pervasive in the social sciences and has been for quite some time. For centuries scholars have analyzed books, laws, documents, and interview transcripts to learn about the world … It would be a mistake to suppose that new computer-assisted text analysis could replace this long research tradition by eliminating the need for careful and close readings of texts or otherwise obviating the need for human analysis. Rather, computer-assisted text analysis augments our reading ability. New text analysis methods help us read differently, not avoid reading at all.
(Grimmer et al. 2022:24, EMPHASIS ADDED)
Key Principles
(3) Iteration and Cumulation Are Paramount
[T]he iterative and cumulative approach to social science … is not atheoretical. Rather, each stage of the research process is informed by theory. The process can also help us build new theoretical explanations and then test those explanations … Learning from data, updating theories, and then testing those revised theories is a big move away from how social science is typically taught. But … [w]e see this iterative and cumulative description of social science as a more accurate account of how social science research tends to be done.
(Grimmer et al. 2022:26, EMPHASIS ADDED)
Key Principles
(4) Text Analysis Distills Linguistic Complexity
The goal of text analysis methods is to develop a distillation that reduces … (linguistic) complexity to something simpler. We … often talk about this in the language of mathematics, referring to text as high-dimensional because any dataset that could represent all of each text’s information in numbers would need many, many features or columns … Text analysis methods are about compressing high-dimensional information in the text to a lower-dimensional representation, where that representation retains the content that is useful for a particular social science research agenda.
(Grimmer et al. 2022:28, EMPHASIS ADDED)
Key Principles
(5) The “Best” Method Depends on the Task
[R]esearchers should try several methods, evaluate their performance, and select the one that best helps them accomplish their goal … The performance of different methods varies substantially across the types of texts we analyze, which vary in length, content, formality, and grammatical structure … We also advocate for a task-specific approach to applying text analysis methods because the features of interest vary based on what we want to learn from the text … The types of quantities that social scientists hope to extract from texts are diverse and constantly growing.
(Grimmer et al. 2022:31, EMPHASIS ADDED)
Key Principles
(6) Validations Are Essential, Too
[E]ven if our method is able to produce accurate unit-level measures, we still have to validate that we are measuring our concept of interest. Thus, research projects will typically involve several validation steps … One feature that is common to many … validation methods is that they place “humans in the loop,” explicitly relying on human judgment in a partially automated process that incorporates two key insights. First, for many tasks we want to assess models based on how humans use the information the model provides. Second, to include human information we need to carefully design experiments to ensure that researchers avoid arbitrary criteria when choosing the model.
(Grimmer et al. 2022:29–30, EMPHASIS ADDED)
Two Quick Examples
Radical Politics
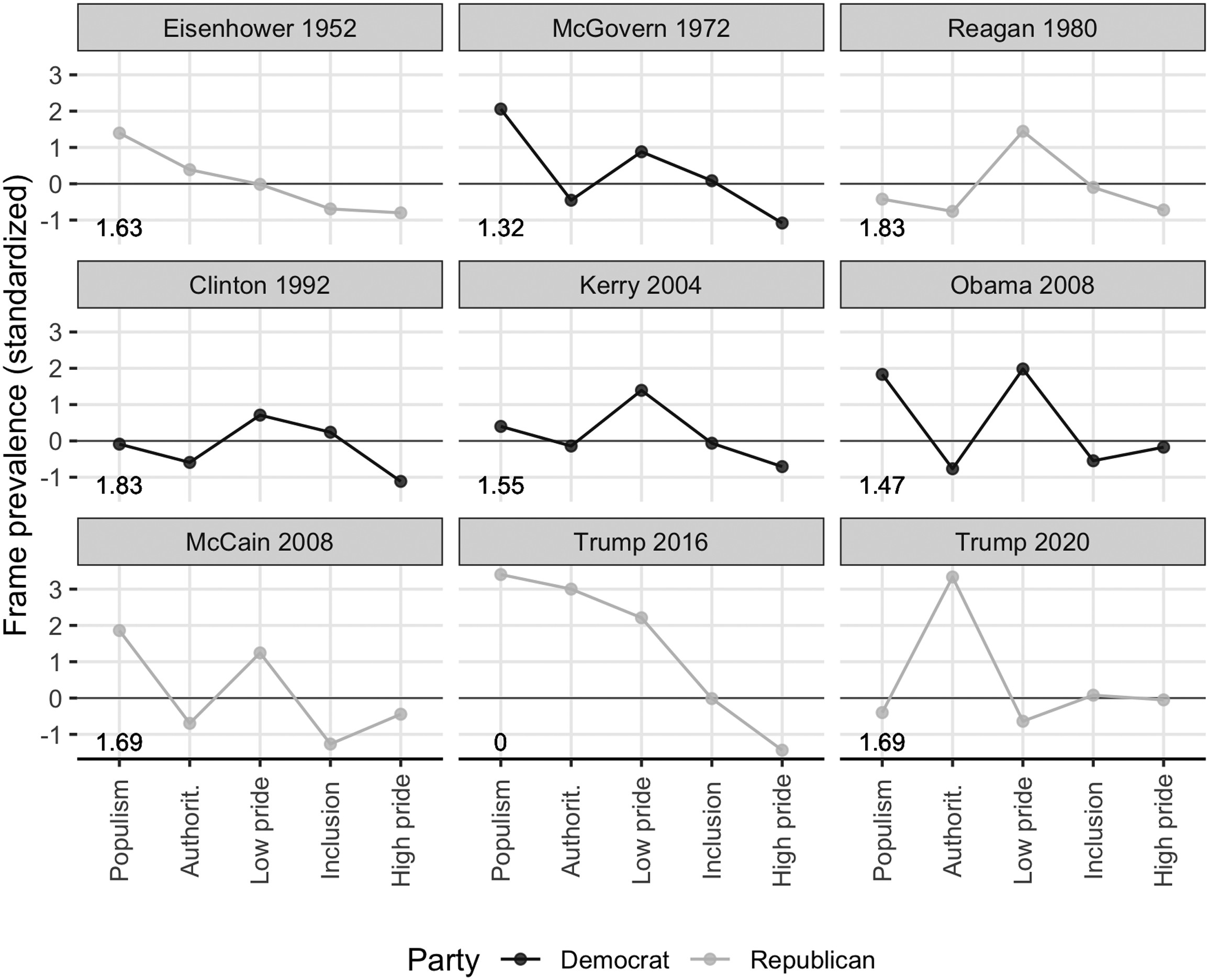
Figure 5 from Bonikowski, Luo and Stuhler (2022)
Temporalities of Climate Change
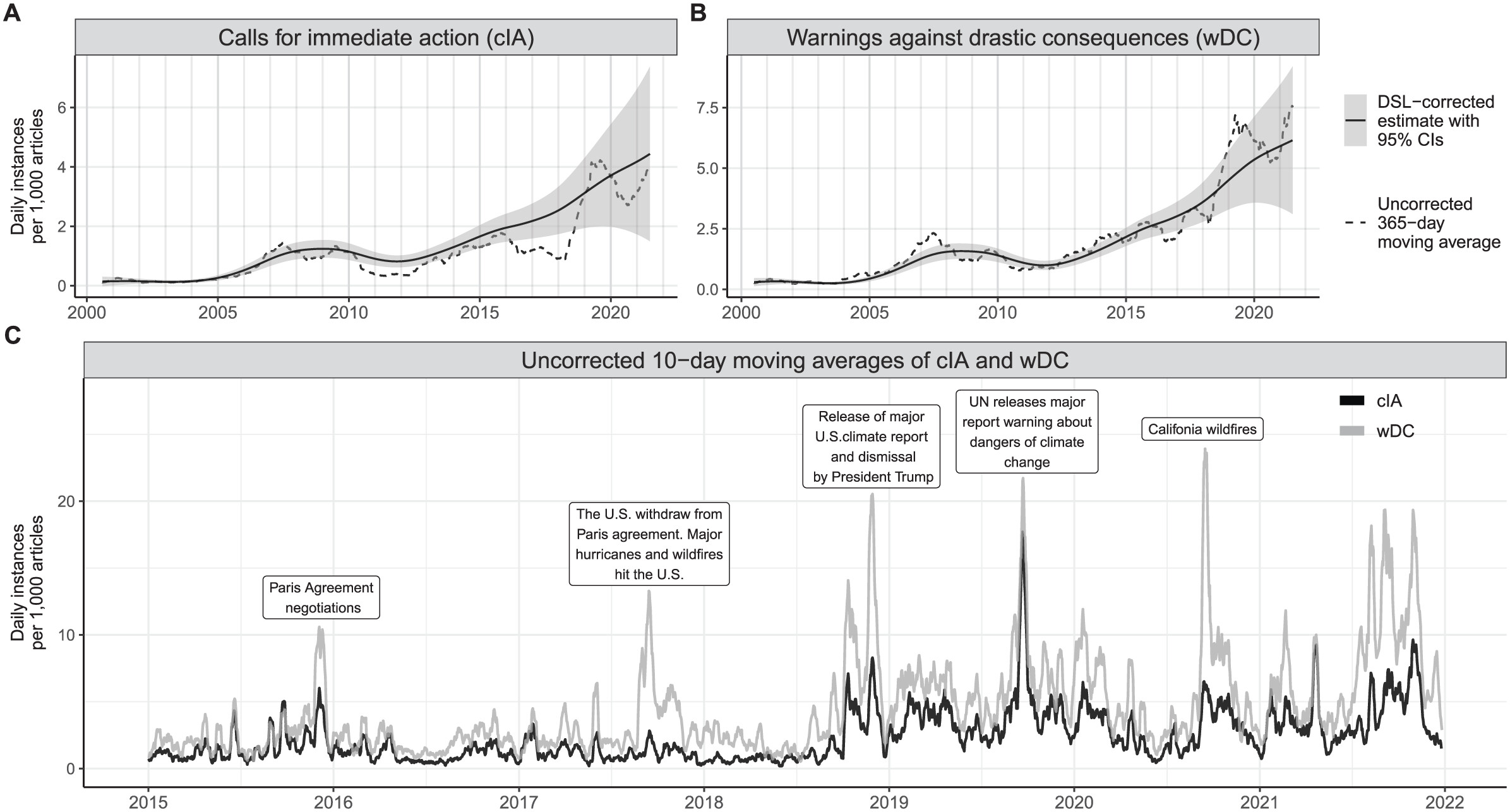
Figure 7 from Stuhler, Tavory, and Wagner-Pacifici (2026)
Work Session
Surveys and Bibliographies
For the rest of today’s session, please
work on your Qualtrics surveys
or annotated bibliographies.
See You on Thursday
References
Bonikowski, Bart, Yuchen Luo, and Oscar Stuhler. 2022. “Politics as Usual? Measuring Populism, Nationalism, and Authoritarianism in U.S. Presidential Campaigns (1952–2020) with Neural Language Models.” Sociological Methods & Research 51(4):1721–87. doi: 10.1177/00491241221122317.
Bonikowski, Bart, and Laura K. Nelson. 2022. “From Ends to Means: The Promise of Computational Text Analysis for Theoretically Driven Sociological Research.” Sociological Methods & Research 51(4):1469–83. doi: 10.1177/00491241221123088.
Grimmer, Justin, Margaret E. Roberts, and Brandon M. Stewart. 2022. Text as Data: A New Framework for Machine Learning and the Social Sciences. Princeton University Press.
Stuhler, Oscar, Iddo Tavory, and Robin Wagner-Pacifici. 2026. “Time and Climate Change: U.S. Media Representations of Climate Actions, Horizons, and Events (2000 to 2021).” American Sociological Review 91(1):158–89. doi: 10.1177/00031224251403596.
